

What is Web Scraping?
There is a lot of data available on the internet, that is useful for Companies, Businesses, Governments, and so on. That is a good thing. But what’s worse is there is a lot of data available on the internet. Allow me to explain.
Suppose you are looking for a job and you go to naukri.com. Now there are a lot of jobs that you need to go through. Clicking the next infinite amount of times made you wonder, am I ever going to find the right company? isn’t there any way I can get access to all the jobs in one place?
Web scraping, as the name suggests, scrapes all the data that you need from the internet and it is a really cool skill to have. It’s almost magic.
What do you need to Scrape the data:
Python:
If you know python, you know web scraping is going to be very easy for you. Python offers a lot of Web Scraping libraries that do the task for you.
So What are we going to scrape today?
So We are going to scrape the data from timesjobs.com.
We will scrape the job postings for python in timesjobs. The information that we are going to Scrape is the Company name, Skills, and years of experience that employers need.
So what Libraries do we need?
BeautifulSoup :
Beautiful Soup is a Python library for pulling data out of HTML and XML files. It commonly saves programmers hours or days of work.
requests:
Requests allows you to send HTTP/1.1 requests extremely easily. There’s no need to manually add query strings to your URLs or to form-encode your POST data.
lxml:
lxml is a Python library that allows for easy handling of XML and HTML files, and can also be used for web scraping. The key benefits of this library are that it’s the ease of use, extremely fast when parsing large documents, very well documented, and provides easy conversion of data to Python data types, resulting in easier file manipulation.
How to install BeautifulSoup and requests
Go to your editor terminal. To install BeautifulSoup:
pip install bs4To install requests:
pip install requestsTo install lxml:
pip install lxmlWeb scraping Step 1: Import all the libraries
from bs4 import BeautifulSoup
import requests
Web scraping Step 2: Get the URL we need to scrape
Go to timesjobs.com and search python and you will get a URL something like this:
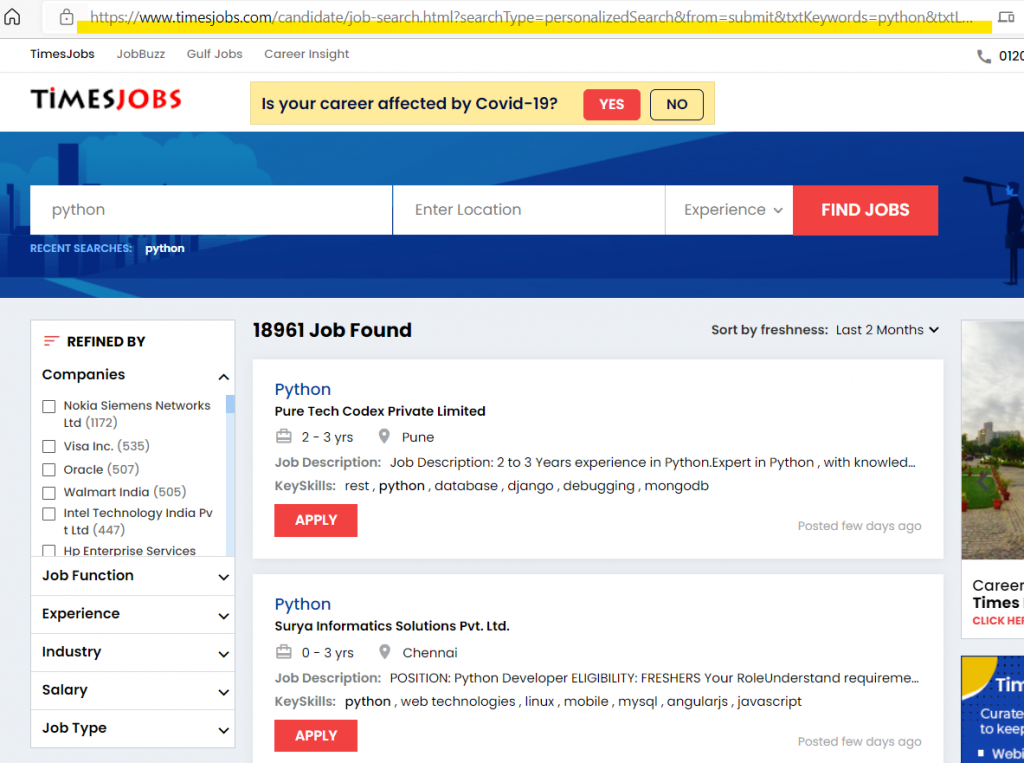
we are going to store this URL in a variable for later use.
url = 'https://www.timesjobs.com/candidate/job-search.html?searchType=personalizedSearch&from=submit&txtKeywords=python&txtLocation='Web scraping Step 3 :
Now we will get the source code of our webpage by using requests.
html_text = requests.get(url).text
print(html_text)Output of the following code:
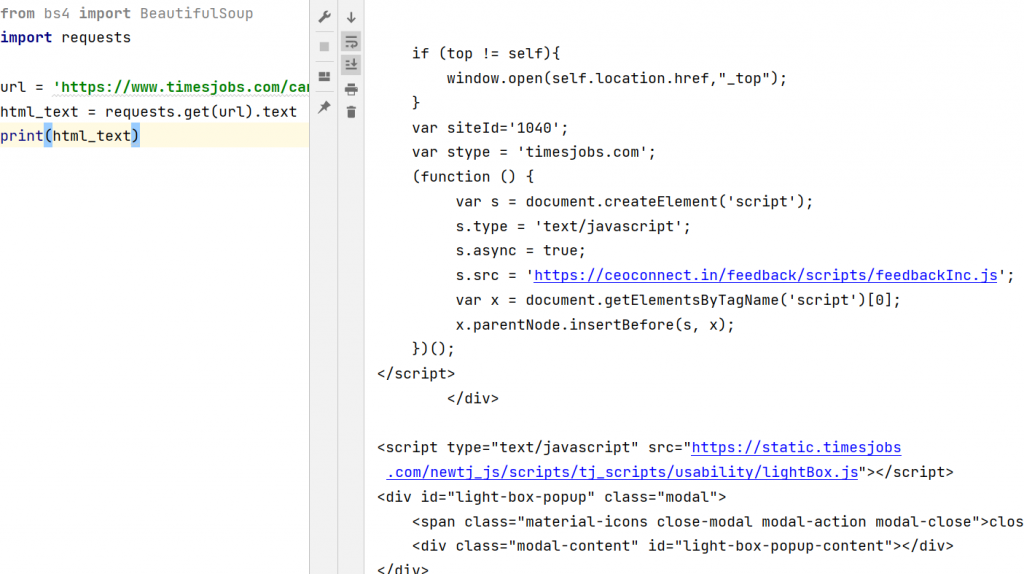
Now that we have source code of our web page, we are going to use BeautifulSoup on it.
Web scraping Step 3: BeautifulSoup Our Webpage
soup = BeautifulSoup(html_text,'lxml')
print(soup)Output of the following Code:
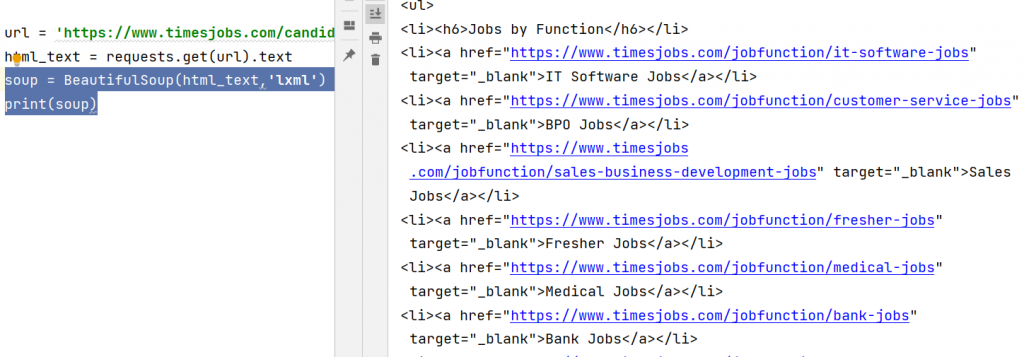
If you are following all the steps, you have noticed our HTML file is not readable, you can make it readable by using prettify() method.
print(soup.prettify())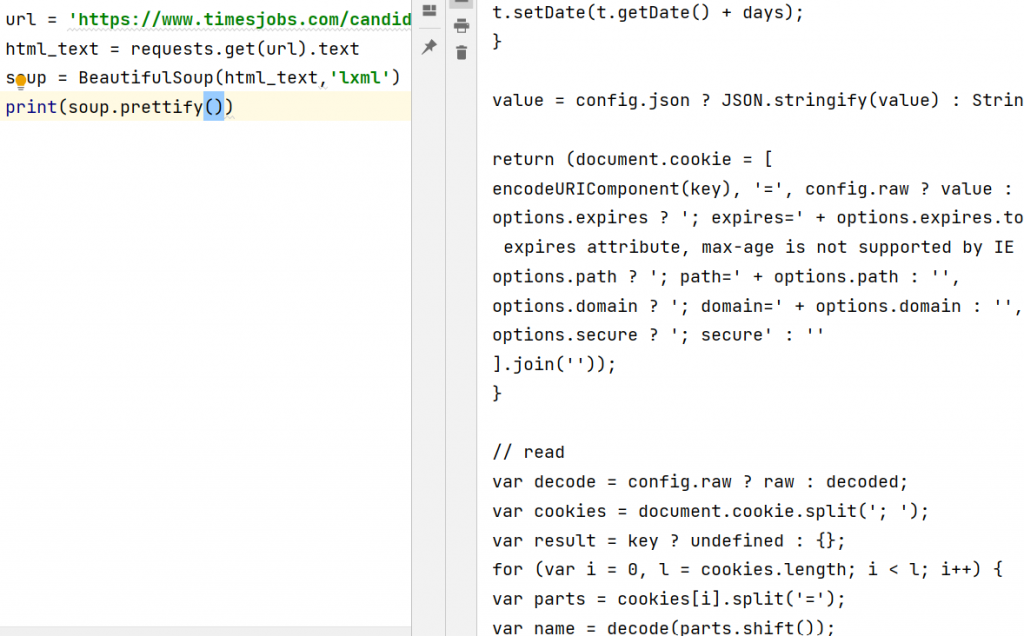
Web scraping Step 4: To Scrape The Data From Our Webpage
You must have heard about the inspect element. inspect element comes in handy and is very useful when scraping the data. We want to scrape the data from job postings, so we need to scrape the job postings box first if we want to scrape all the necessary information.
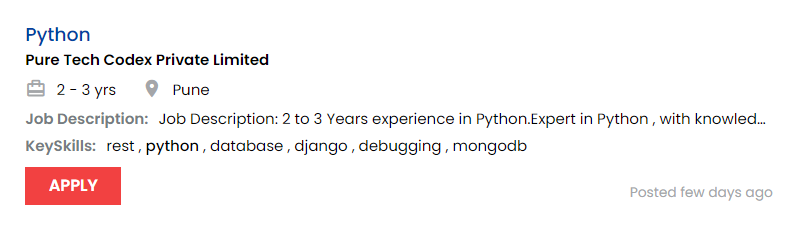
If we go to the inspect element of this box, we will get this:
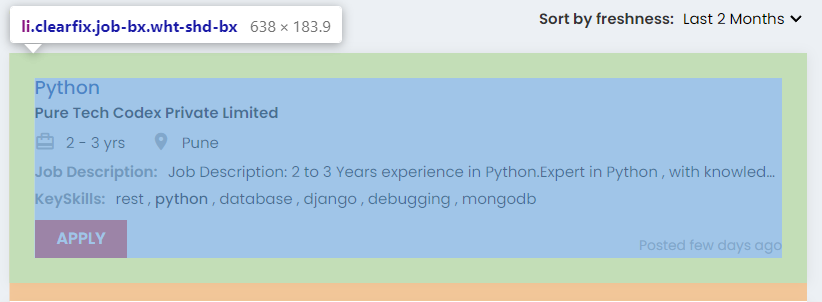
This is the li tag that stores all the job postings:

So to scrape this job posting we need to find this tag with its class name.
jobs = soup.find('li','clearfix job-bx wht-shd-bx')
print(jobs)
Web scraping Step 5: To Scrape Company, Skills, and Experience Required
Company Name :
find() method gives the first <li> tag. But we do not want the whole tag, We want the company name and the company name is in the <li> tag that we just scraped. Company name is in <h3> tag with class name ‘joblist-comp-name’.
company_name = jobs.find('h3','joblist-comp-name').text.strip()
print(company_name)Output of the following code:
Pure Tech Codex Private LimitedSkills :
skills are in <span> tag with the class name srp-skills.
skills = jobs.find('span', 'srp-skills').text.strip()
print(skills)
Output of the following code:
rest,python,database,django,debugging,mongodbExperience:
Experience lies under <li> tag that lies under <ul> with class :
'top-jd-dtl clearfix'
experience = jobs.find('ul','top-jd-dtl clearfix').find('li').text
print(experience)Output of the following code :
card_travel2 - 3 yrsNow card_travel is a string that comes with experience, so we are going to replace it with an empty string. So we are going to modify the above code.
experience = jobs.find('ul','top-jd-dtl clearfix').find('li').text.replace('card_travel','')
print(experience)Output of the following code:
2 - 3 yrs
What have we accomplished by now? (Whole Code)
#Web scraping timesjobs.com
from bs4 import BeautifulSoup
import requests
url = 'https://www.timesjobs.com/candidate/job-search.html?searchType=personalizedSearch&from=submit&txtKeywords=python&txtLocation='
html_text = requests.get(url).text
soup = BeautifulSoup(html_text,'lxml')
jobs = soup.find('li','clearfix job-bx wht-shd-bx')
company_name = jobs.find('h3','joblist-comp-name').text.strip()
skills = jobs.find('span', 'srp-skills').text.strip().replace(' ','')
experience = jobs.find('ul','top-jd-dtl clearfix').find('li').text.replace('card_travel','')
print('Company Name : ',company_name)
print('Skills Required :',skills)
print('Experience : ',experience)Output of the following Code :
Company Name : Pure Tech Codex Private Limited
Skills Required : rest,python,database,django,debugging,mongodb
Experience : 2 - 3 yrsNow we have scraped only one company information but we need all the information that is on our webpage, for that we will use find_all method and will do a little change in our code
from bs4 import BeautifulSoup
import requests
url = 'https://www.timesjobs.com/candidate/job-search.html?searchType=personalizedSearch&from=submit&txtKeywords=python&txtLocation='
html_text = requests.get(url).text
soup = BeautifulSoup(html_text, 'lxml')
jobs = soup.find_all('li', 'clearfix job-bx wht-shd-bx')
for job in jobs:
company_name = job.find('h3', 'joblist-comp-name').text.strip()
skills = job.find('span', 'srp-skills').text.strip()
posted = job.find('span', 'sim-posted').span.text
experience = job.find('ul', 'top-jd-dtl clearfix')
year = experience.find('li').text.replace('card_travel', '')
print(f'Company Name : {company_name}')
print(f'skills : {skills}')
print(f'Experience : {year}')
print('--------------------------------------------------------------------')
Output :
#Web scraping
C:\Users\abhis\PycharmProjects\pythonProject5\venv\Scripts\python.exe C:/Users/abhis/PycharmProjects/pythonProject5/webscraping.py
Company Name : Pure Tech Codex Private Limited
skills : rest , python , database , django , debugging , mongodb
Experience : 2 - 3 yrs
--------------------------------------------------------------------
Company Name : Surya Informatics Solutions Pvt. Ltd.
skills : python , web technologies , linux , mobile , mysql , angularjs , javascript
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : Gemini Solutions
skills : python , mobile , svn , nosql , python scripting , git , api , sql database
Experience : 4 - 7 yrs
--------------------------------------------------------------------
Company Name : RESEARCH DEVELOPERS
(More Jobs)
skills : python , research , python programmer , Machine Learning , Pattern Recognition , Image Processing , Digital Image , Signal Processing , Electronic Circuits , Network Analysis
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : TEAMPLUS STAFFING SOLUTION PVT. LTD.
skills : python , python scripting , shell scripting , unix
Experience : 6 - 9 yrs
--------------------------------------------------------------------
Company Name : 2COMS Consulting Pvt Ltd
(More Jobs)
skills : Python Developer
Experience : 3 - 7 yrs
--------------------------------------------------------------------
Company Name : TECHNOPARK TRIVANDRUM
skills : fundamentals , python , programming language
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : GS LAB
skills : python , linux , debugging , unix
Experience : 3 - 5 yrs
--------------------------------------------------------------------
Company Name : Ivan Infotech Pvt. Ltd.
skills : rest , python , security , debugging
Experience : 2 - 5 yrs
--------------------------------------------------------------------
Company Name : HIRING STREET
(More Jobs)
skills : python , , Django , Jquery
Experience : 2 - 6 yrs
--------------------------------------------------------------------
Company Name : TECHNOPARK TRIVANDRUM
skills : python , oops , storage
Experience : 2 - 5 yrs
--------------------------------------------------------------------
Company Name : TandA HR Solutions
skills : Django framework , Python Developer , core python
Experience : 3 - 5 yrs
--------------------------------------------------------------------
Company Name : Datagrid Solutions
skills : python , database , django , mysql , api
Experience : 2 - 3 yrs
--------------------------------------------------------------------
Company Name : east india securities ltd.
skills : python , hadoop , machine learning
Experience : 2 - 5 yrs
--------------------------------------------------------------------
Company Name : sjain ventures
skills : python , web developer , web services
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : systango
skills : python , django , javascript , web programming
Experience : 5 - 8 yrs
--------------------------------------------------------------------
Company Name : TandA HR Solutions
skills : python , django , sql
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : METADESIGN SOLUTIONS
skills : python , django , html5 , javascript
Experience : 2 - 5 yrs
--------------------------------------------------------------------
Company Name : APPLYCUP HIRING SOLUTIONS LLP
skills : python , Django , Object Relational Mapper
Experience : 3 - 5 yrs
--------------------------------------------------------------------
Company Name : 47Billion Information Technologies Pvt Ltd
skills : python , security , django , html5 , javascript , docker
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Company Name : BR Raysoft Global Pvt Ltd
(More Jobs)
skills : Python , Django
Experience : 4 - 9 yrs
--------------------------------------------------------------------
Company Name : Merkle Inc.
skills : algorithms , python , svn , nosql , oop , git , devops
Experience : 3 - 6 yrs
--------------------------------------------------------------------
Company Name : TandA HR Solutions
skills : python , git , django
Experience : 2 - 5 yrs
--------------------------------------------------------------------
Company Name : TandA HR Solutions
skills : python , git , django
Experience : 5 - 8 yrs
--------------------------------------------------------------------
Company Name : TEAMPLUS STAFFING SOLUTION PVT. LTD.
skills : Python 2 , knowledge of JIRA , Terraform
Experience : 0 - 3 yrs
--------------------------------------------------------------------
Process finished with exit code 0
Conclusion:
Now, this is how you can scrap data from timesjobs by using web scraping. If you have followed this tutorial, you can start scraping any sites using BeautifulSoup.
Go through our Courses Here :
Python for Data Analytics | Console Flare
Masters in Datascience with Power BI | Console Flare

Follow us on Instagram: Console Flare (@consoleflare) is on Instagram

One thought on “How To Start Web scraping With Python- Beautiful Soup”