Data Science Interview Questions
If you are looking for a job role in data science, you must be confused how to prepare for it.
Not anymore. Although there are few platforms for learning in data science. Some of them are really effective.
One of the website that you can go through is stratascratch.com.
Sign in to their website and you will find three types of Questions.
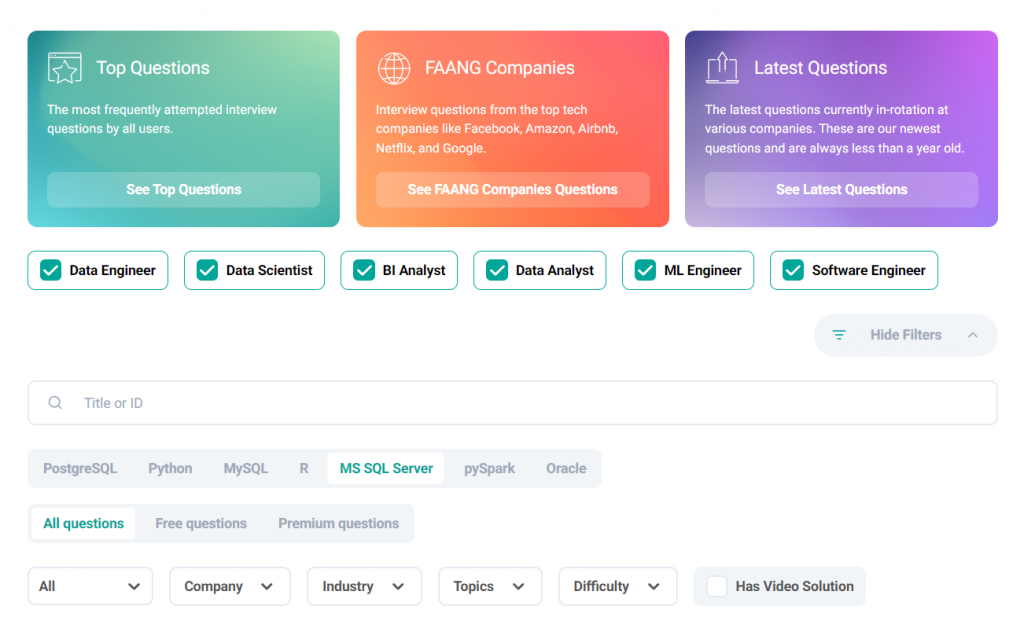
As you can see there are questions classified in three groups.
- Top Questions : the most frequently attempted interview questions
- FAANG Questions
- Latest Questions : Questions that have been revolving around
It does not only offer this , it also offers questions related to different job roles too.
We have also sum up most important questions that you can go through and solve.

Find whether the number of seniors works at Meta/Facebook is higher than its number of USA based employees
Interview Question Date: April 2020
Data science interview questions
Find whether the number of senior workers (i.e., more experienced) at Meta/Facebook is higher than number of USA based employees at Facebook/Meta.
If the number of seniors is higher then output as 'More seniors'. Otherwise, output as 'More USA-based'.
Table: facebook_employeesAnswer:
SELECT
CASE
WHEN n_seniors > n_usa_based
THEN 'More seniors'
ELSE 'More USA-based'
END AS winner
FROM
(SELECT
SUM(CASE WHEN is_senior THEN 1 ELSE 0 END) AS n_seniors
FROM
facebook_employees) seniors
LEFT JOIN
(SELECT
COUNT(*) AS n_usa_based
FROM
facebook_employees
WHERE
location = 'USA'
) us_based
ON TRUEExplanation:
- Subquery 1 (seniors):
- This subquery calculates the total number of senior employees at Facebook.
- It counts the number of employees who are considered seniors (assuming there’s a column named
is_seniorwhich indicates whether an employee is a senior or not) and assigns it ton_seniors.
- Subquery 2 (us_based):
- This subquery calculates the total number of Facebook employees based in the USA.
- It counts the number of employees whose location is marked as ‘USA’ and assigns it to
n_usa_based.
- Main Query:
- It selects a winner based on the comparison of
n_seniorsandn_usa_based. - It compares the total number of senior employees (
n_seniors) with the total number of USA-based employees (n_usa_based). - If the total number of senior employees is greater than the total number of USA-based employees, it returns ‘More seniors’. Otherwise, it returns ‘More USA-based’.
- It selects a winner based on the comparison of
- LEFT JOIN:
- It joins the results of the two subqueries.
- Since it’s a LEFT JOIN, all rows from the
seniorssubquery are returned, along with matching rows from theus_basedsubquery if any. This ensures that even if there are no USA-based employees, the query still returns a result.
- CASE Statement:
- The
CASEstatement evaluates the condition. - If the total number of senior employees is greater than the total number of USA-based employees, it returns ‘More seniors’. Otherwise, it returns ‘More USA-based’.
- The
So, in simple terms, this query compares the number of senior employees at Facebook with the number of employees based in the USA and determines which group is larger, then labels the larger group as the “winner”.
Try to do rest of questions on your own.
Distinct Salaries
Interview Question Date: April 2019
Data science interview questions
Find the top three distinct salaries for each department. Output the department name and the top 3 distinct salaries by each department. Order your results alphabetically by department and then by highest salary to lowest.
Table: twitter_employeeYour Output should be :

Count the number of user events performed by MacBookPro users
Data science interview questions
Count the number of user events performed by MacBookPro users.
Output the result along with the event name.
Sort the result based on the event count in the descending order.
Table: playbook_eventsAnswer:

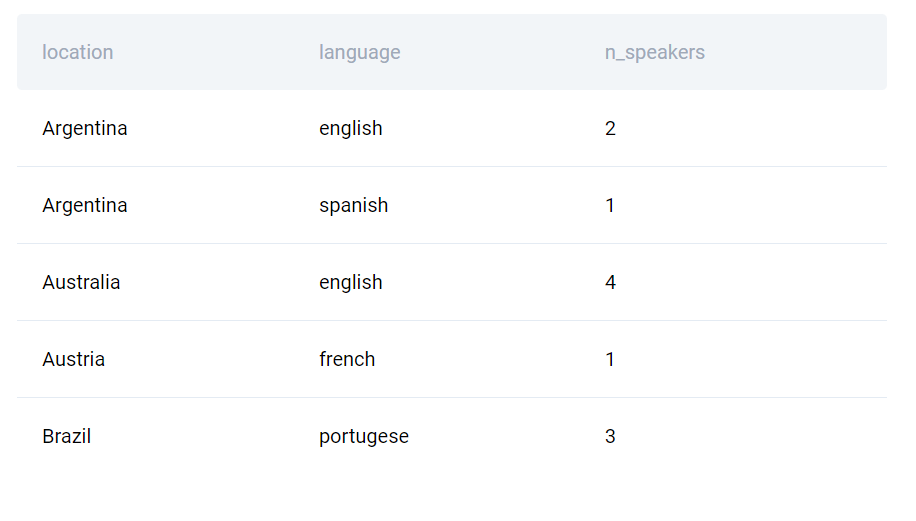
Number of Speakers By Language
Data science interview questions
Find the number of speakers of each language by country. Output the country, language, and the corresponding number of speakers. Output the result based on the country in ascending order.
Tables: playbook_events, playbook_usersAnswer :

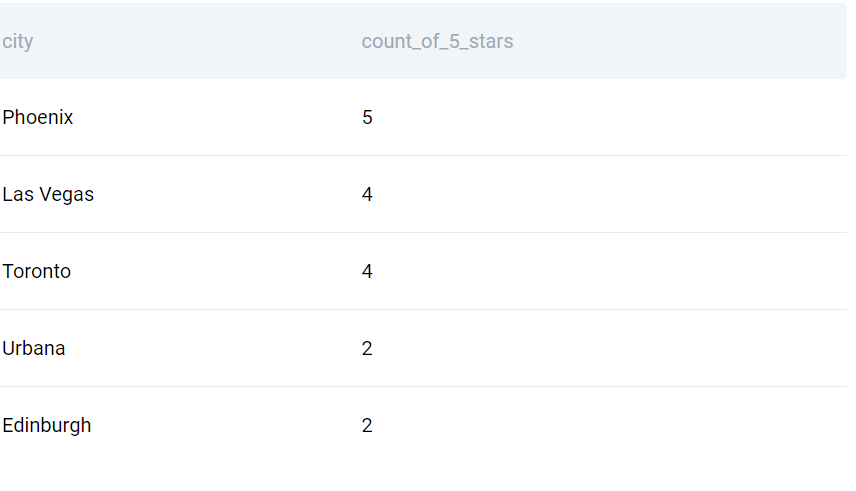
Find the top 5 cities with the most 5 star businesses
Data science interview questions
Find the top 5 cities with the most 5 star businesses
Find the top 5 cities with the most 5-star businesses. Output the city name along with the number of 5-star businesses. Include both open and closed businesses.
In the case of multiple cities having the same number of 5-star businesses, use the ranking function returning the lowest rank in the group and output cities with a rank smaller than or equal to 5.
Table: yelp_businessAnswer:

Find the day of the week that most people check-in
Data science interview questions
Find the day of the week that most people want to check-in.
Output the day of the week alongside the corresponding check-incount.
Table: airbnb_contactsAnswer:

Python Dictionary

GroupBy or OrderBY
Iphone and weblogs
Comparing Performance of Engines
Books Collection
Finding Invalid Schools
Data science interview questions
How many high schools that people have listed on their profiles are real? How do we find out, and deploy at scale, a way of finding invalid schools?Answer 1: Use Facebook data about users and schools.
Approach: Create a graph/cluster of similar users based on their location, age, etc. If some school has only one or a few occurrences it’s probably fake. Instead of looking at similar users, we can only consider user’s friends (and maybe friends of friends) to make this more scalable. It’s very likely that the user’s Facebook friends attend the same school as a user. Another idea is to use school data on Facebook to verify its invalidity. If a school does not have a picture or the school’s name is abnormal, there’s a big chance it’s fake (we can use Machine Learning for this).
Pros: We depend only on app data, we can make the solution scalable.
Cons: If there is not enough application data, our approach will not work. And even if there is, there is no 100% certainty it’s correct. If some school is new and/or users have not updated the high school info it’s possible we claim the high school as invalid, even though it is not invalid.
Answer 2: Use government data that is publicly accessible.
Approach: Fetch a list of schools and compare the user’s school with this list.
Pros: Very quick and probably 100% correct.
Cons: Such access is not a common thing in most countries. Also, we depend on outside sources and if the source is not working we can’t use it.
Answer 3: Reporting mechanism.
Approach: Give an option to users to report invalid high schools of other users. Based on the number of reports make a decision if a school is invalid.
Pros: Simple solution that depends on users’ activity.
Cons: It’s not 100% secure. Also, it could be hard to motivate users for making such explicit actions.
Interview Question #24: Mean, Median Age in Mexico

Link to the question: https://platform.stratascratch.com/technical/2013-mean-median-age-in-mexico/
Answer:
To find out which one is higher between the mean and the median, we need to find out first how the age distribution looks like in Mexico. As a rule of thumb, we can determine which one is higher with the following scenario:
If the age is normally distributed, the mean is going to be equal to the median.
If the age distribution is right-skewed, then the mean is larger than the median.
If the age distribution is left-skewed, then the median is higher than the mean.
According to Statista, which you can see more in detail via this link: https://www.statista.com/statistics/275411/age-distribution-in-mexico, Mexico constantly has a right-skewed distribution from 2010 until 2020.
People ages 0-14 occupy 25-29% of the total population in Mexico.
People ages 15-64 occupy 64-66% of the total population in Mexico.
People ages above 65 occupy 6-7% of the total population in Mexico.
Thus, the mean age in Mexico is higher than the median.
The more theoretical question could be one by Travelport:
Interview Question #25: R^2 Value

Link to the question: https://platform.stratascratch.com/technical/2153-r2-value
A little bit of formulas writing is tested by FINRA question:
Interview Question #26: Pearson’s Correlation Coefficient

Interview Question #27: Survey Response Randomness

Link to the question: https://platform.stratascratch.com/technical/2205-survey-response-randomness
Do you know how to answer this data science interview question? A slight hint: Cronbach’s alpha. Now you have to elaborate on this.
The question for those that will be more into machine learning is this one by DST Systems:
Interview Question #28: Variance in Unsupervised Model

“How to calculate variance in an unsupervised model?”
Data science interview questions Link to the question: https://platform.stratascratch.com/technical/2210-variance-in-unsupervised-model
You could do it on an example of k-means clustering. To get the variance of the model, you’ll have to define the formula of both within-cluster and between-cluster variations separately.
Deloitte is interested in the Shapiro-Wilk test:
Interview Question #29: Shapiro-Wilk Test
Data science interview questions Link to the question: https://platform.stratascratch.com/technical/2331-shapiro-wilk-test
What is it used for? Do you need the null hypothesis, and how do you form it? How does the p-value compare with the significance level? Those are all questions that could frame your approach to answering the question.
The Modeling Data Science Interview Questions
When you get the modeling questions, they will test your knowledge about machine learning and statistical modeling. That means you need to show how you’d use these technical skills to generate sample data and predict real-world events.
Here’s one such question by Amazon:
Interview Question #30: Colinearity in Data Analysis
Data science interview questions Link to the question: https://platform.stratascratch.com/technical/2140-colinearity-in-data-analysis
Answer:
What is Collinearity or Multicollinearity?
Collinearity typically occurs during regression analysis and can happen when one independent variable in a regression model is linearly correlated with another independent variable.
Why Collinearity becomes a problem?
When we are dealing with regression analysis, we will get a fitted coefficient for all of the independent variables that contribute to the result of the dependent variable, for example:
� = 2 + 0.4�1 + 0.5�2Y = 2 + 0.4X1 + 0.5X2
In the equation above, Y is the dependent variable, while X1 and X2 are the independent variables. We normally can interpret the coefficient (in the equation above 0.4 for X1 and 0.5 for X2) of each independent variable as the contribution of one specific independent variable ( for example X1) to the dependent variable (Y) when we change the value of that independent variable (X1) while keeping the value of another independent variable (X2) constant.
If we have collinearity, this means that if we change the value of X1, the coefficient of X2 would most likely change as well, which makes it difficult for us to interpret the model and the statistics.
The variance of the model might get inflated due to collinearity, which might give us a ‘false’ p-value result. This would lead us to the confusion to pick which independent variables are statistically significant that need to be included in the final regression model.
How to deal with Collinearity?
There are two common ways to deal with collinearity:
- Using Variance Inflation Factor or VIF.
VIF measures the ratio between the variance for a given coefficient with only the corresponding independent variable in the model versus the variance for a given coefficient with all independent variables in the model.
A VIF of 1 means the tested independent variable is not correlated with the other predictors. VIF of 1-5 indicates medium collinearity. Meanwhile, VIF above 5 indicates strong collinearity with other independent variables. - Using Correlation Matrix
A correlation matrix normally shows us the Pearson’s correlation between two independent variables. If Pearson’s correlation between two independent variables is above 0.75, we can consider that those two independent variables have high collinearity.
Without understanding at least in theory what a machine learning concept is, you won’t get a job. This Salesforce data scientist interview question tests this nicely:
Interview Question #31: Machine Learning Concept
Link to the question: https://platform.stratascratch.com/technical/2042-machine-learning-concept
Similarly phrased question is the one by SparkCognition on the random forest:
Interview Question #32: Random Forrest
Data science interview questions Link to the question: https://platform.stratascratch.com/technical/2070-random-forrest
Try it yourself; it’s potentially not as easy as you might think. Of course, you know what a random forest is. But you have to explain it in non-technical terms. If you can do it, then you really understand!
In your modeling, you’ll also use linear and logistic regression. No wonder IBM is interested in knowing how you’ll handle this question:
Interview Question #33: Logistic Regression and Linear Regression
Data science interview questions Link to the question: https://platform.stratascratch.com/technical/2089-logistic-regression-and-linear-regression
You’ll also be working with algorithms, be it your or someone else’s. That’s why it’s essential to know the answer to this data science interview question from Netflix:
Interview Question #34: Better Algorithm

Link to the question: https://platform.stratascratch.com/technical/2108-better-algorithm
The unavoidable step of modeling is a model evaluation. You’ll have to show you’re familiar with it by answering the General Assembly question:
Interview Question #35: Model Evaluation Procedures
Link to the question: https://platform.stratascratch.com/technical/2120-model-evaluation-procedures
For example, you could come across this data science interview question by Southwest Airlines:
Data science interview questions: UNION and UNION ALL
Link to the question: https://platform.stratascratch.com/technical/2083-union-and-union-all
Answer:
UNION and UNION ALL are SQL statements that are useful to concatenate the entries between two or more tables. In general, they have the same functionality.
The main difference between UNION and UNION ALL is that the UNION command will only extract the relevant entries that are unique (no duplicates) while UNION ALL will extract all of the relevant entries, including the duplicates.
You see, while you didn’t have to write an SQL code containing UNION or UNION ALL, you still had to know what these two SQL statements do.
Speaking of SQL, you could be required to explain the difference between different joins. For example, like in this Credit Acceptance question:
Data science interview questions: Left Join and Right Join
Link to the question: https://platform.stratascratch.com/technical/2242-left-join-and-right-join
We shouldn’t forget Python is also massively used in data science. That’s why you should also know something about Python’s dictionary to answer the Moore Capital Management question:
Interview Question #38: Python Dictionary
Link to the question: https://platform.stratascratch.com/technical/2091-python-dictionary
A hint? The answer should have something to do with hash tables. Wink-wink, nudge-nudge.
The questions don’t have to be about the programming languages concepts. The Goldman Sachs question is one such example:
Data science interview questions: Square Root of Two
Link to the question: https://platform.stratascratch.com/technical/2229-square-root-of-two
The questions could be concerning data, like in this IBM question:
Data science interview questions: Dealing with Missing Values

Link to the question: https://platform.stratascratch.com/technical/2255-dealing-with-missing-values
The answer should involve describing which two types of data could be missing and how you fill the missing data in each data type.
Not only the data but the interview question could also test your theoretical knowledge of databases. One of the popular questions is the one by Deloitte on database normalization:
Data science interview questions: Database Normalization
Link to the question: https://platform.stratascratch.com/technical/2330-database-normalization
You should know what the purpose of database normalization is. Then you should list all the steps in this process and explain how this step fulfills the goal of normalization.
The Product Data Science Interview Questions
The product questions are the least universal questions you could get at an interview. They are designed to test your knowledge of the specific company’s product(s). That way, they’re not only testing your problem-solving skills but also how familiar you are with the company itself and its products. The ideal scenario would be to be a long-time customer itself.
Visa could be interested in credit card activity:
Interview Question #42: Credit Card Activity

Link to the question: https://platform.stratascratch.com/technical/2342-credit-card-activity
Another question asking to show your product knowledge is the one by eBay:
Data science interview questions: Identify Ebay Objects

Link to the question: https://platform.stratascratch.com/technical/2075-identify-ebay-objects
Yammer, on the other hand, is interested in reports on the content upload:
Data science interview questions: Spike in Uploads
Link to the question: https://platform.stratascratch.com/technical/2044-spike-in-uploads
Being an Instagram and Facebook user could help you find the answer to this data science interview question easier:
Data science interview questions: Investigate the Discrepancy
Link to the question: https://platform.stratascratch.com/technical/2203-investigate-the-discrepancy
Google has numerous products, with one of them being Google One. It’s not necessary to be a subscriber to answer this question, but it probably won’t hurt knowing how this product works:
Interview Question #46: Storage Plan Usage
Link to the question: https://platform.stratascratch.com/technical/2303-storage-plan-usage
And if you were a Skype user (or you weren’t and you know why!) during the COVID-19 pandemic, maybe you would quickly answer this question by Microsoft:
Interview Question #47: Skype Usage

Link to the question: https://platform.stratascratch.com/technical/2321-skype-usage
As you can see, you don’t have to be an avid user of every product possible. But you should at least make yourself familiar with the products the company offers. That is especially important if you apply for some product-specific positions. It’s also helpful to know different types of product interview questions in detail.
Conclusion
In preparing for a data science job interview, there’s a vast range of question types you should cover. Two main types are coding and non-coding data science interview questions.
While the coding questions are the most common, coding is not the only skill you need to have. That’s why the non-coding questions are equally important. Their purpose is to show your statistics, modeling, and system design skills, along with product knowledge, problem-solving, and other technical skills.
This guide gives you an overview of the range of questions that await you at the data science interview for top companies. It’s not an easy task to get a job in such companies. Going through all these data science questions is only a starting point. Now is your turn to explore all other coding and non-coding interview questions.
If you wish to learn more about data science or want to curve your career in the data science field feel free to join our free workshop on Masters in Data Science with PowerBI, where you will get to know how exactly the data science field works and why companies are ready to pay handsome salaries in this field.
In this workshop, you will get to know each tool and technology from scratch that will make you skillfully eligible for any data science profile.
To join this workshop, register yourself on consoleflare and we will call you back.
Thinking, Why Console Flare?
- Recently, ConsoleFlare has been recognized as one of the Top 10 Most Promising Data Science Training Institutes of 2023.
- Console Flare offers the opportunity to learn Data Science in Hindi, just like how you speak daily.
- Console Flare believes in the idea of “What to learn and what not to learn” and this can be seen in their curriculum structure. They have designed their program based on what you need to learn for data science and nothing else.
- Want more reasons,