

Data Lake vs Data Warehouse: Meaning & Key Differences
In the ever-evolving world of data management, two terms that often find themselves at the center of discussions are “Data Lake” and “Data Warehouse.” These are two distinct approaches to storing and processing data, each with its unique strengths and use cases.
In this article, we will delve into the differences between a Data Lake and a Data Warehouse, their architectures, and their respective roles in modern data-driven businesses.
Understanding Data Lake and Data Warehouse
Data Lake Meaning
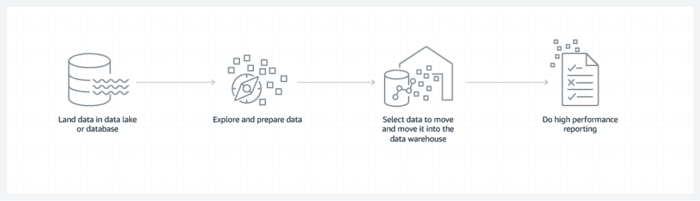
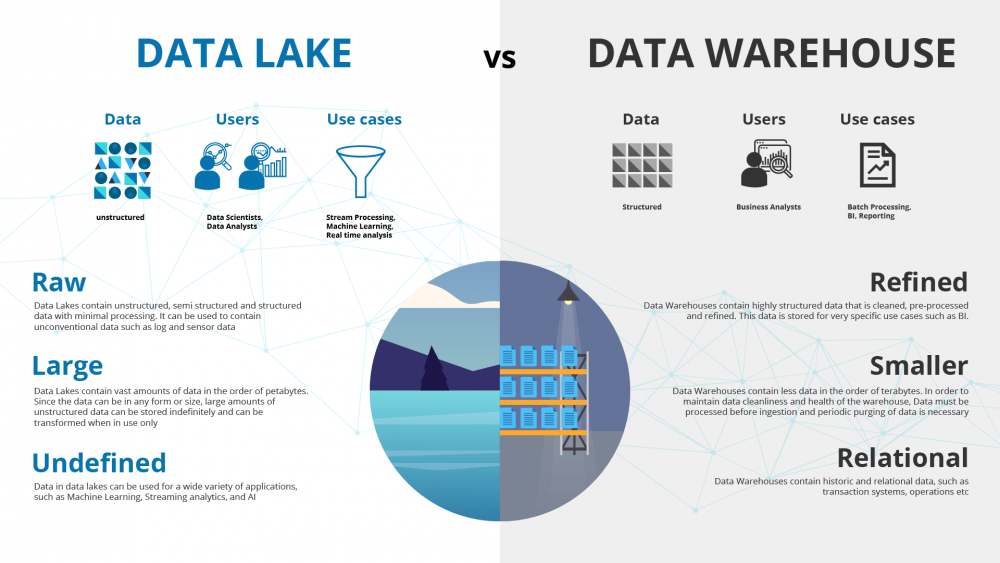
A Data Lake is a vast repository that stores raw, unprocessed data from multiple sources in its native format. It provides a centralized location for storing structured, semi-structured, and unstructured data, such as text, images, videos, log files, and more. Unlike traditional databases, a Data Lake doesn’t enforce a schema beforehand, allowing for more flexibility in data exploration and analysis.
You’re reading the article, Data Lake vs Data Warehouse: Key Differences You Should Know.
Data Warehouse Meaning
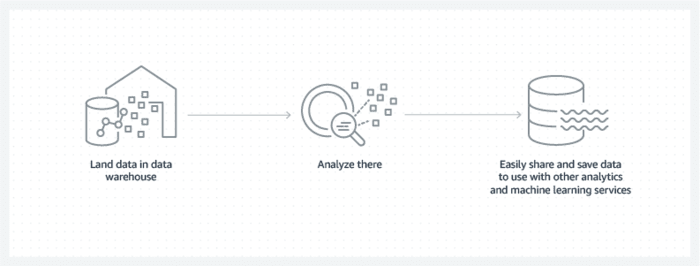
On the other hand, a Data Warehouse is a structured and optimized database that stores processed and transformed data from various sources. It follows a predefined schema and stores data in a well-organized manner to facilitate efficient querying and analysis. Data Warehouses are designed to support business intelligence (BI) and reporting applications.
Data Lake vs. Data Warehouse: Key Differences
- Data Structure: Data Lake vs Data Warehouse
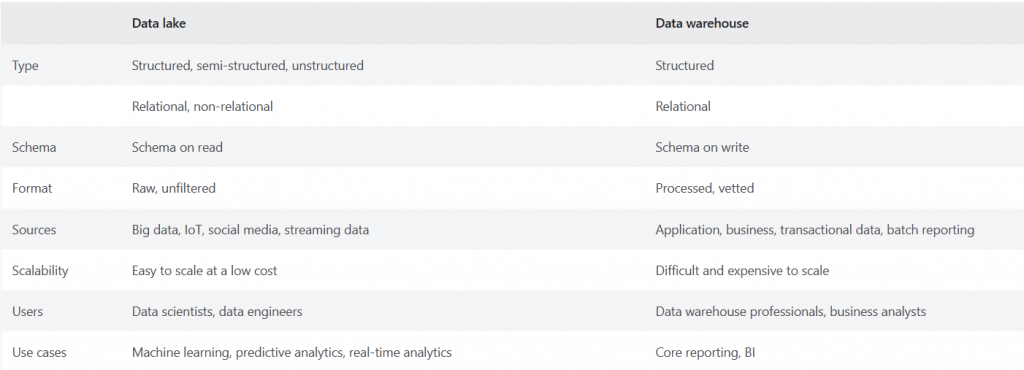
In a Data Lake, data is stored in its raw and native format, without any predefined structure or restrictions. This flexibility allows data scientists and analysts to explore and experiment with various data formats and extract valuable insights. In contrast, a Data Warehouse enforces a schema, which means the data must be transformed and structured before being loaded into the warehouse. This structured approach ensures data consistency and accuracy but may limit the agility in handling diverse data types. - Data Processing: Data Lake vs Data Warehouse
Data Lakes are ideal for storing large volumes of raw data, making them suitable for big data processing and analytics. Data is ingested into the lake before any processing takes place, enabling batch and real-time data analysis. Data Warehouses, however, involve a process known as Extract, Transform, Load (ETL), where data is extracted from source systems, transformed to fit the warehouse schema, and then loaded into the warehouse. This process can be time-consuming, but it ensures that data is clean and structured for precise reporting. - Schema-on-Read vs. Schema-on-Write: Data Lake vs Data Warehouse
A significant difference between the two lies in their schema approach. Data Lakes follow a “Schema-on-Read” model, meaning the schema is applied when the data is read or queried. This offers greater flexibility since different users can interpret the data as needed. Data Warehouses, on the other hand, adopt a “Schema-on-Write” model, where the schema is defined during data ingestion. This upfront schema definition streamlines data retrieval but may limit adaptability to changing business requirements. - Data Usage and Users: Data Lake vs Data Warehouse
Data Lakes are well-suited for data exploration, machine learning, and ad-hoc analytics. Data scientists and data engineers can access the raw data, experiment with different algorithms, and create models without the constraints of predefined schemas. On the contrary, Data Warehouses are optimized for business users and analysts who need structured data for business reporting, dashboarding, and decision-making. - Cost Considerations: Data Lake vs Data Warehouse
Data Lakes are generally more cost-effective for storing massive amounts of raw data due to their scalability and use of low-cost storage solutions like Hadoop Distributed File System (HDFS) or cloud-based object storage. In contrast, Data Warehouses are designed for performance and query optimization, often requiring higher-cost infrastructure to ensure rapid data retrieval.
You’re reading the article, Data Lake vs Data Warehouse: Key Differences You Should Know.
Data Lake Architecture
A typical Data Lake architecture consists of three layers: the data ingestion layer, the storage layer, and the processing layer. Data is ingested from various sources, stored in the lake in its raw form, and then processed when needed for analysis. Popular tools used for building Data Lakes include Apache Hadoop, Apache Spark, and cloud-based platforms like Amazon S3 and Microsoft Azure Data Lake Storage.
Data Warehouse Architecture
Data Warehouses follow a structured architecture with two primary components: the data integration layer and the data storage layer. The data integration layer handles ETL processes, transforming and cleansing data before loading it into the storage layer. The storage layer is often a relational database, optimized for querying and reporting, with star or snowflake schema designs.
You’re reading the article, Data Lake vs Data Warehouse: Key Differences You Should Know.
Data Lake vs. Delta Lake
Delta Lake is an extension of Data Lakes that add ACID (Atomicity, Consistency, Isolation, Durability) transactions and schema enforcement to the raw data. This means Delta Lake combines the advantages of Data Lakes (flexibility, scalability) with the reliability and data quality features of Data Warehouses. For example, if a data scientist wants to perform machine learning on data stored in Delta Lake, they can be confident that the data’s integrity remains intact.
Data Lake on Azure
Microsoft Azure offers Azure Data Lake Storage, a cloud-based storage service optimized for big data workloads. Azure Data Lake Storage provides a scalable and cost-effective solution for building Data Lakes in the Azure ecosystem.
You’re reading the article, Data Lake vs Data Warehouse: Key Differences You Should Know.
Conclusion
In conclusion, both Data Lakes and Data Warehouses play crucial roles in the data management landscape. Data Lakes excel in handling raw and diverse data for exploration and experimentation, while Data Warehouses are tailored for structured data processing and business intelligence. Understanding the strengths and differences between these two approaches is essential for businesses aiming to derive maximum value from their data assets.
Whether you opt for the flexibility of a Data Lake or the structured efficiency of a Data Warehouse, a well-designed data strategy will undoubtedly empower your organization to thrive in the data-driven era.
Hope you liked reading the article, Data Lake vs Data Warehouse: Key Differences You Should Know. Please share your thoughts in the comments section below.

