


In the world of data science, where accuracy and efficiency are key, ensuring data consistency is critical. One of the challenges data scientists often face is handling inconsistencies in textual data. Whether it’s misspelled user inputs or slight variations in product names, these small differences can lead to bigger issues, affecting data quality and outcomes. This is where the Levenshtein Distance Method becomes an invaluable tool.
What is the Levenshtein Distance Method?
The Levenshtein Distance is a measure of how different two strings are. It counts the number of single-character edits (insertions, deletions, or substitutions) required to change one word into another. For example, the Levenshtein distance between “kitten” and “sitting” is 3 because three changes (substituting ‘k’ for ‘s’, replacing ‘e’ with ‘i’, and adding a ‘g’ at the end) are needed to make the two words identical.
Why is Levenshtein Distance Important?
In data science, we often deal with messy, real-world data where users input information that may not match exactly. Consider scenarios such as:
- User search queries on e-commerce websites that contain typos
- Differing product names across datasets
- Data entry errors when managing large datasets
Using the Levenshtein distance method, we can find the closest match between strings, cleaning the data and improving its quality.
Example:
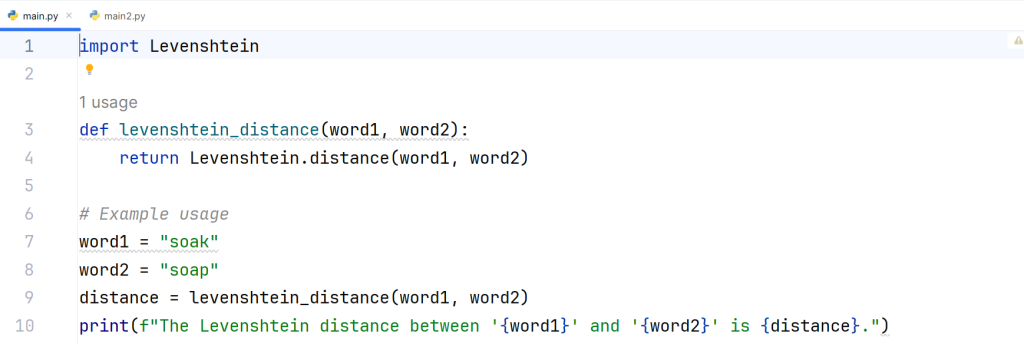
# install levenshtein library
import Levenshtein
def levenshtein_distance(word1, word2):
return Levenshtein.distance(word1, word2)
# Example usage
word1 = "soak"
word2 = "soap"
distance = levenshtein_distance(word1, word2)
print(f"The Levenshtein distance between '{word1}' and '{word2}' is {distance}.")
# Output-- The Levenshtein distance between 'kitten' and 'setting' is 4.

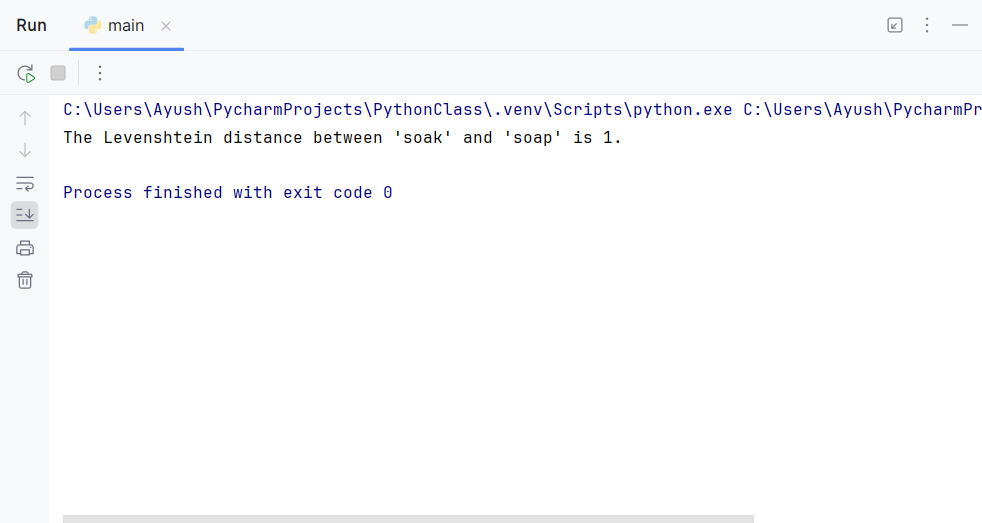
Explanation: The Levenshtein distance between “kitten” and “sitting” is 4 because four changes (replacing ‘k’ for ‘s’, replacing ‘i’ with ‘e’, replacing ‘e’ with ‘i’, and adding a ‘g’ at the end) are needed to make the two words identical.
For more such content and regular updates, follow us on Facebook, Instagram, LinkedIn
Why is Levenshtein Distance Important in Data Science?
The Levenshtein distance method is crucial in many real-world data science applications. For example:
- Text Matching: In search engines, correcting typos in user queries by finding the closest possible match from a database of products or services.
- Data Cleansing: Identifying and correcting spelling errors in large datasets, ensuring that records can be correctly matched or processed.
- Recommendation Systems: Helping systems suggest relevant results even when the input is slightly off.
By using the Levenshtein distance, data scientists can reduce human errors, improve the accuracy of machine learning models, and ensure better data integrity.
Example: Correcting User Search Data: Let’s explore a more practical use case. Imagine you’re working for an e-commerce platform where users often misspell the names of the products they are searching for. We can use the Levenshtein method to automatically correct these mistakes and match them to the correct product in the database.
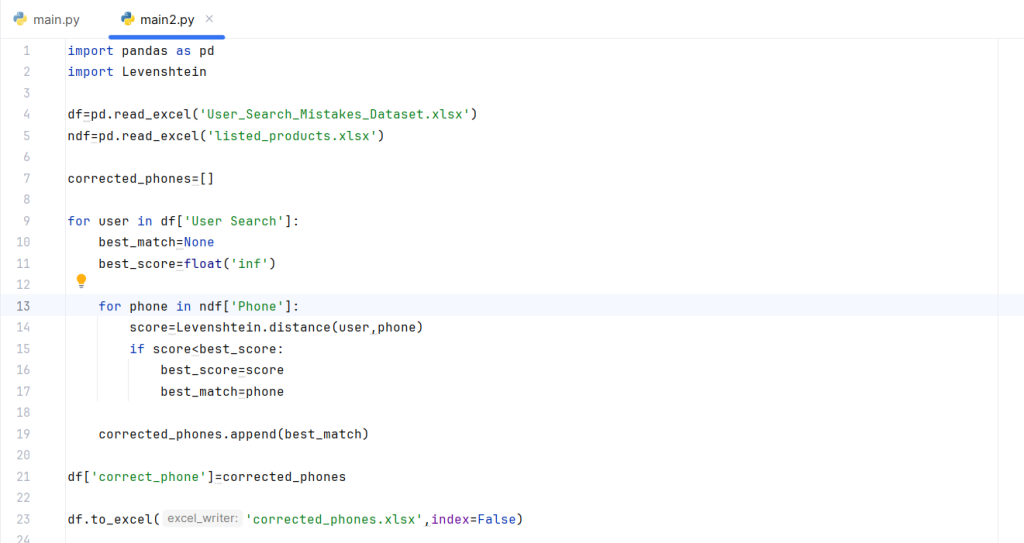
import pandas as pd
import Levenshtein
# Load user search mistakes and listed products
df = pd.read_excel('User_Search_Mistakes_Dataset.xlsx')
ndf = pd.read_excel('listed_products.xlsx')
corrected_phones = []
# Correct user searches by finding the closest match
for user in df['User Search']:
best_match = None
best_score = float('inf')
for phone in ndf['Phone']:
score = Levenshtein.distance(user, phone)
if score < best_score:
best_score = score
best_match = phone
corrected_phones.append(best_match)
# Save corrected search terms to a new file
df['correct_phone'] = corrected_phones
df.to_excel('corrected_phones2.xlsx', index=False)
print("Corrected data has been saved to 'corrected_phones2.xlsx'.")
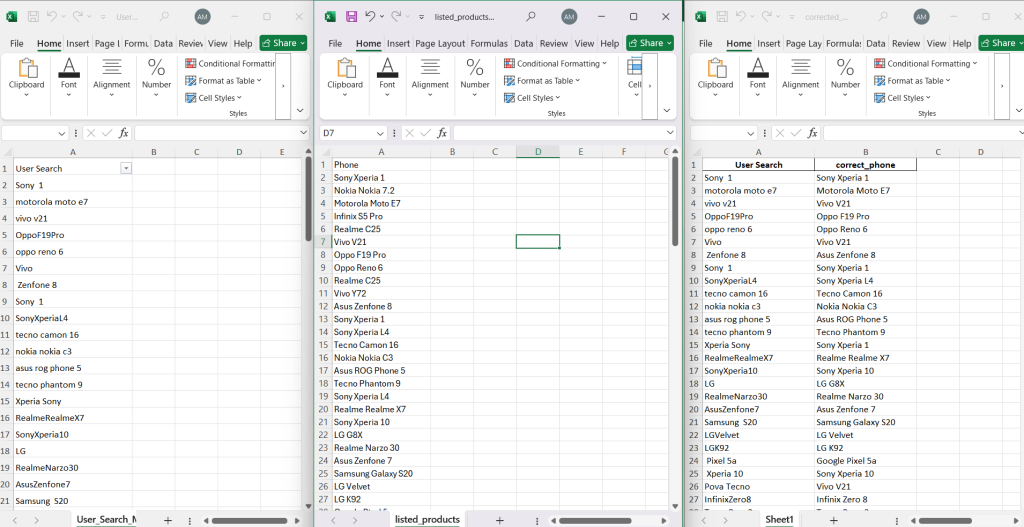
Explanation:
Data Loading: We load two datasets: one containing user search terms (User_Search_Mistakes_Dataset.xlsx) and another with the correct product names (listed_products.xlsx).
Matching Process: For each search term in the user data, we calculate the Levenshtein distance between the user input and every product in the listed products dataset. The product with the smallest distance is chosen as the best match.
Data Output: The corrected search terms are stored in a new column correct_phone, and the updated dataset is saved as an Excel file.

By using this method as a foundation, the e-commerce platform can handle user input errors and still provide the correct product, ensuring a better user experience and more accurate search results.
The Levenshtein distance method is a powerful tool in the data science toolkit. It helps ensure data accuracy, particularly when working with textual data. Whether matching user input to product names, correcting errors in large datasets, or enhancing the accuracy of machine learning models, the Levenshtein distance is a versatile solution to many common problems.
Want to learn more?
If you’re ready to embark on a rewarding career in data science, consider enrolling in a comprehensive course that focuses on relevant skills only.
At ConsoleFlare, we offer tailored courses that provide hands-on experience and in-depth knowledge to help you master Python and excel in your data science journey. Join us and take the first step towards becoming a data science expert with Python at your fingertips.
Register yourself with ConsoleFlare for our free workshop on data science. In this workshop, you will get to know each tool and technology of data analysis from scratch that will make you skillfully eligible for any data science profile.
To join this workshop, register yourself on consoleflare and we will call you back.
Thinking, Why Console Flare?
- Recently, ConsoleFlare has been recognized as one of the Top 10 Most Promising Data Science Training Institutes of 2023.
- Console Flare offers the opportunity to learn Data Science in Hindi, just like how you speak daily.
- Console Flare believes in the idea of “What to learn and what not to learn” and this can be seen in their curriculum structure. They have designed their program based on what you need to learn for data science and nothing else.
- Want more reasons,
Register yourself on consoleflare and we can help you switch your career to Data Science in just 6 months.
Happy coding, future data scientists!